Most APM and DEM use cases focus on using application performance metrics to diagnose poor application response times and reduce time to resolve (MTTR) performance degradations.
However, most IT leaders expect their teams to go beyond reactive application performance management to:
- Proactively optimize user digital experience and application performance (as opposed to reactively fixing application performance issues),
- Extend IT teams’ capabilities to manage the performance of SaaS applications, third-party application components and packaged software applications.
From Troubleshooting to Proactive Application Performance Optimization
Traditionally, the focus of network performance monitoring (NPM) and APM users was MTTR reduction — i.e. using network and application performance metrics and diagnostics to reduce the time window between a degradation and its resolution.
Troubleshooting faster was the main expected benefit of these application performance management tools, and it was achieved by accelerating:
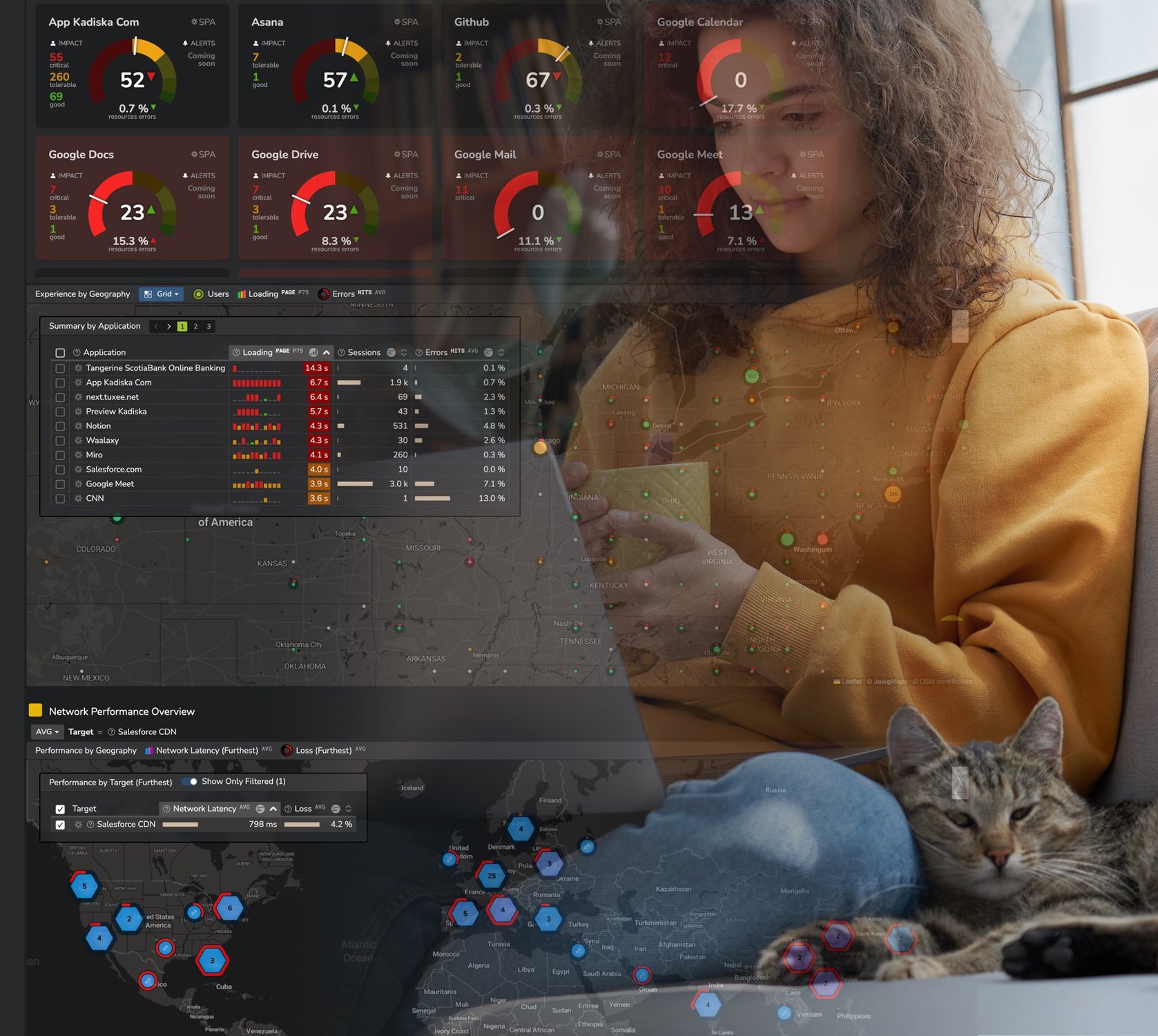
- Scope Analysis of Degradations: Which users are impacted by applications performance issues, for which transactions, when and how often?
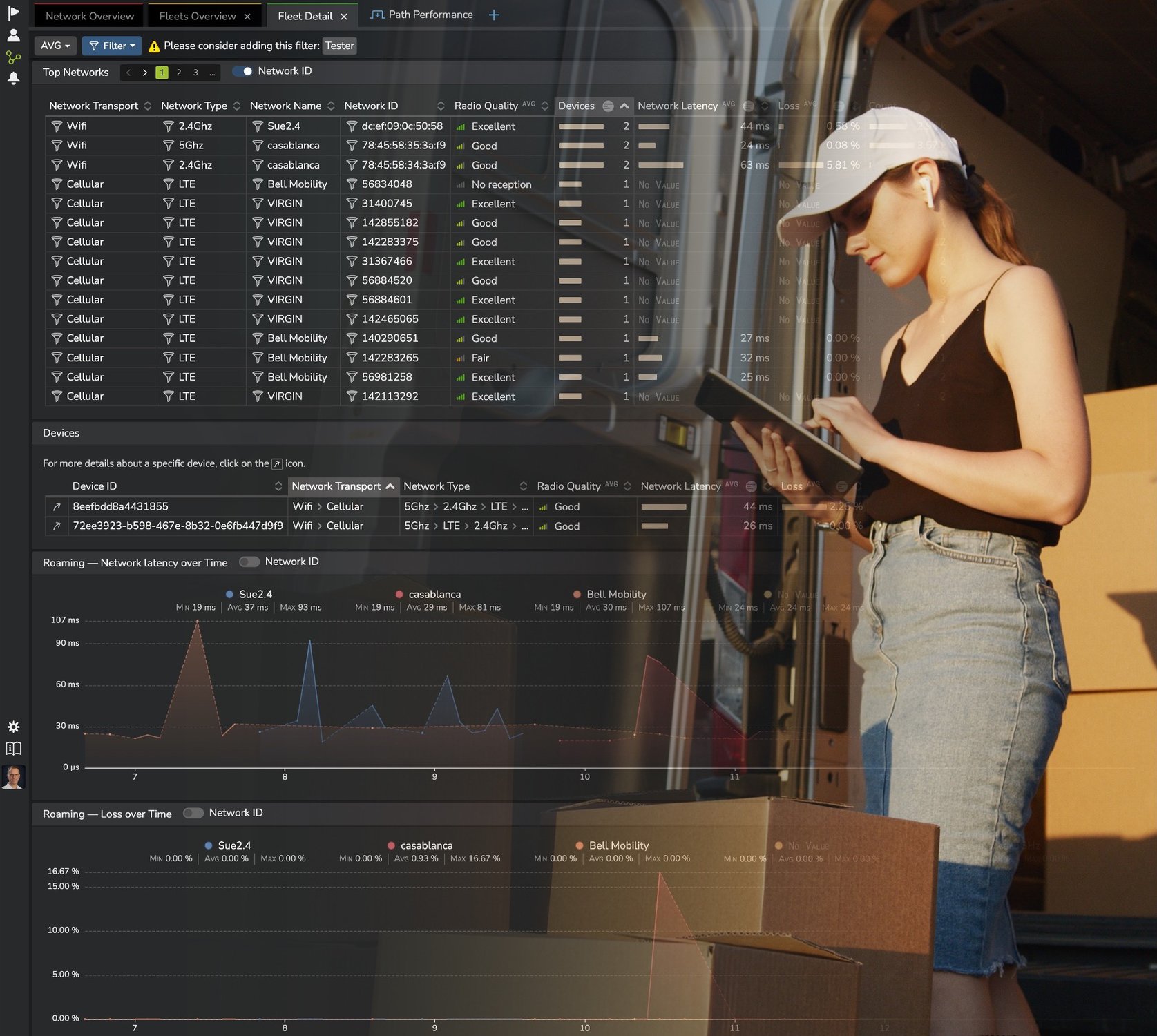
- Fault Isolation: Identify the infrastructure layer responsible for the application performance degradation across network, endpoint, secured gateway, load balancers, front- and back-end servers) to direct the case to the right team for in-depth root cause analysis and performance management.
- Root cause analysis: Pinpoint the change, defect or parameter which is creating the slow processing or errors.
Faster Troubleshooting Isn’t Enough
While the benefit of MTTR reduction is fundamental in application performance management, tools purchased for troubleshooting tend to be used reactively and require scarce, expert-level skills to interpret application performance metrics and perform packet-level data analysis. They also don’t provide insight into SaaS application performance, applications hosted on PaaS, or third-party applications that integrate with them to form composable applications.

IT operations executives at more progressive organisations have set a more aggressive target: monitor application performance proactively, and improve application performance before users complain and productivity is impacted.
There are three ways IT teams can focus efforts on their next move to manage application performance more efficiently:
- Proactive Alerting
- Resolution Validation
- Application Performance Optimization
Let’s take a look at each and how they contribute to proactive application performance management.
Proactive Alerting
The first next step is to move from a situation where you expect users impacted by application performance issues to contact the helpdesk and complain.
Advanced IT operations should aim to catch most performance incidents through proactive alerting, giving them a head start to resolve application performance issues before users complain. This is essential for cloud-hosted, prepackaged and SaaS applications that account for the majority of application performance management issues in large organizations.
Yet, there is a lack of proactive performance management integration into IT processes due to specific challenges:
- Setting up and maintaining relevant thresholds and baselines to trigger alerts is time consuming and inadequate in rapidly changing, highly distributed SaaS and cloud hosted environments served by public and hybrid networks.
- Continued dependence on traditional application performance metrics that focus on page load performance while overlooking transaction processing times and network metrics that largely define the user digital experience in SaaS, and cloud-hosted single page applications (SPA).
- Using the wrong metrics to trigger alerts results in false positives and teams that ‘chase ghosts’ instead of the real root cause. Arcane technical metrics often create more trouble than clarity without deep technical expertise to interpret them in context.
Resolution Validation
Most performance issues have several–sometimes interrelated–causes. Evaluating the impact of each one and how they relate is often very hard. In real life, IT teams end up implementing different fixes then measuring how much improvement resulted from these application performance management efforts.
The only way to reach a level of application performance optimization that improves user satisfaction is to measure application performance as your teams take progressive action. This real-time feedback is essential to ensuring teams have fixed the real root cause(s) of application performance issues impacting the user experience.
Application Performance Optimization
So far, we have discussed how to shift from reactive incident response to proactive and complete application performance management. Moving ahead requires that you take steps not only to resolve degradations, but to actively improve your users’ digital experience.
Proactive application performance management doesn’t stop there, the same approach can also guide strategies to optimize application performance by:
- Providing permanent observability: understand performance rates for each application and user profile, analyze performance drivers and trends to reveal performance optimization opportunities.
- Identify performance bottlenecks and potential improvements at each layer used to deliver the application (endpoint, browser, DNS, LAN, WAN, CASB, SaaS platform, cloud or data center)
- Guide application performance optimization strategies and accelerate their implementation.
- Validate the impact of actions and quantify the benefits to user experience and business productivity.
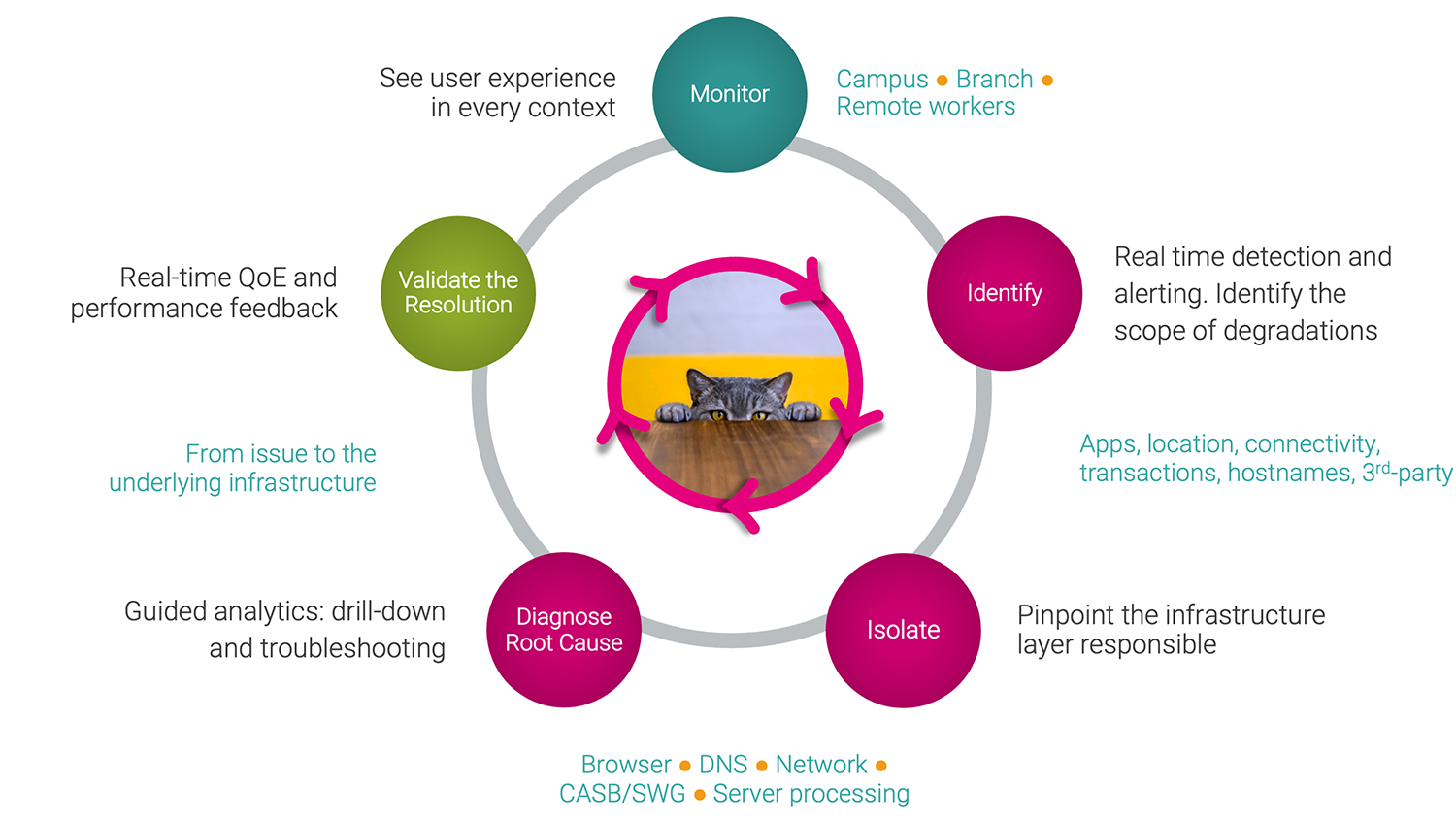
Learn how the real-time combination of network performance and digital user experience monitoring creates 360° visibility into modern network and application infrastructure so IT teams can advance to a proactive and preventive mode of operation.