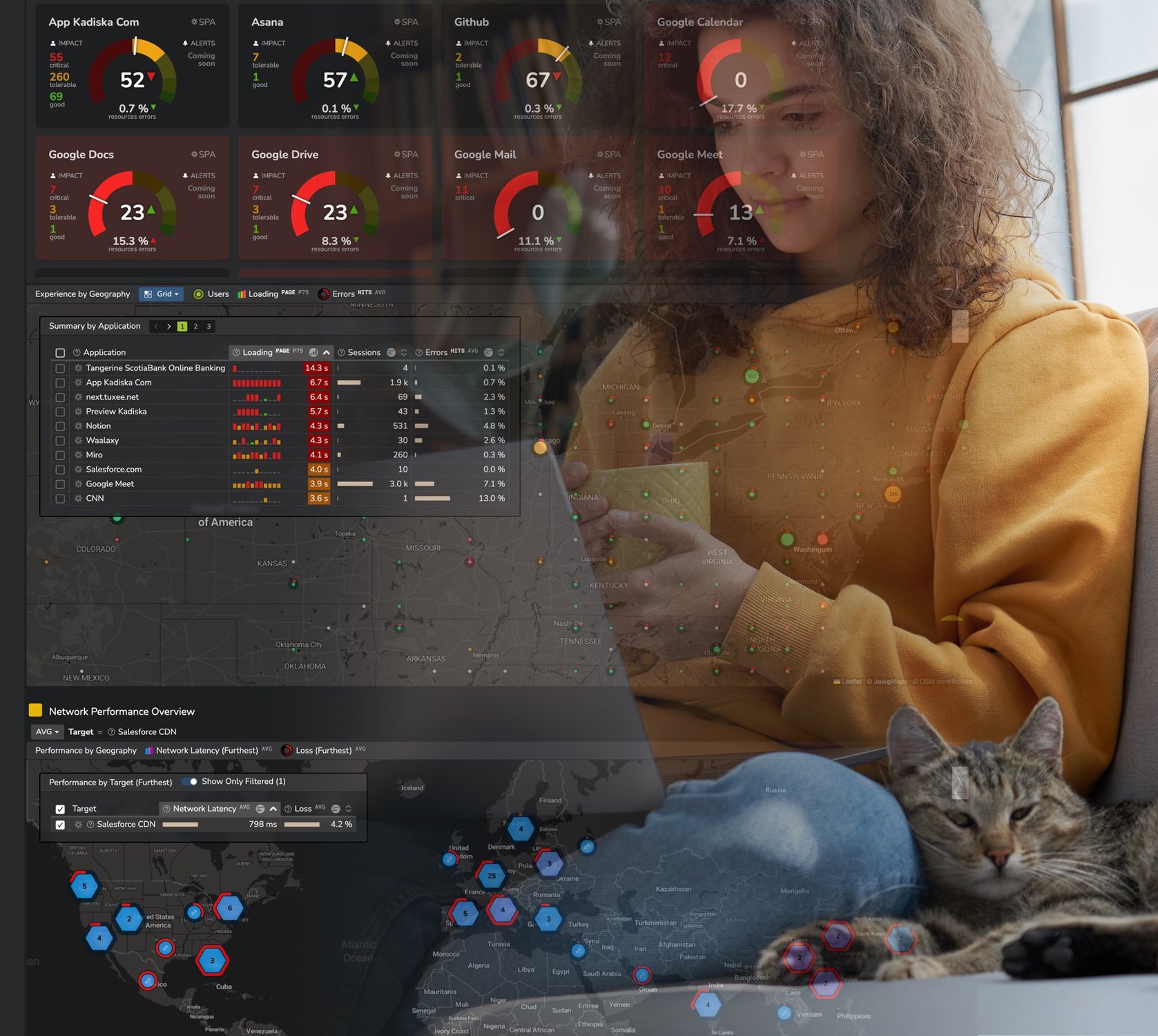
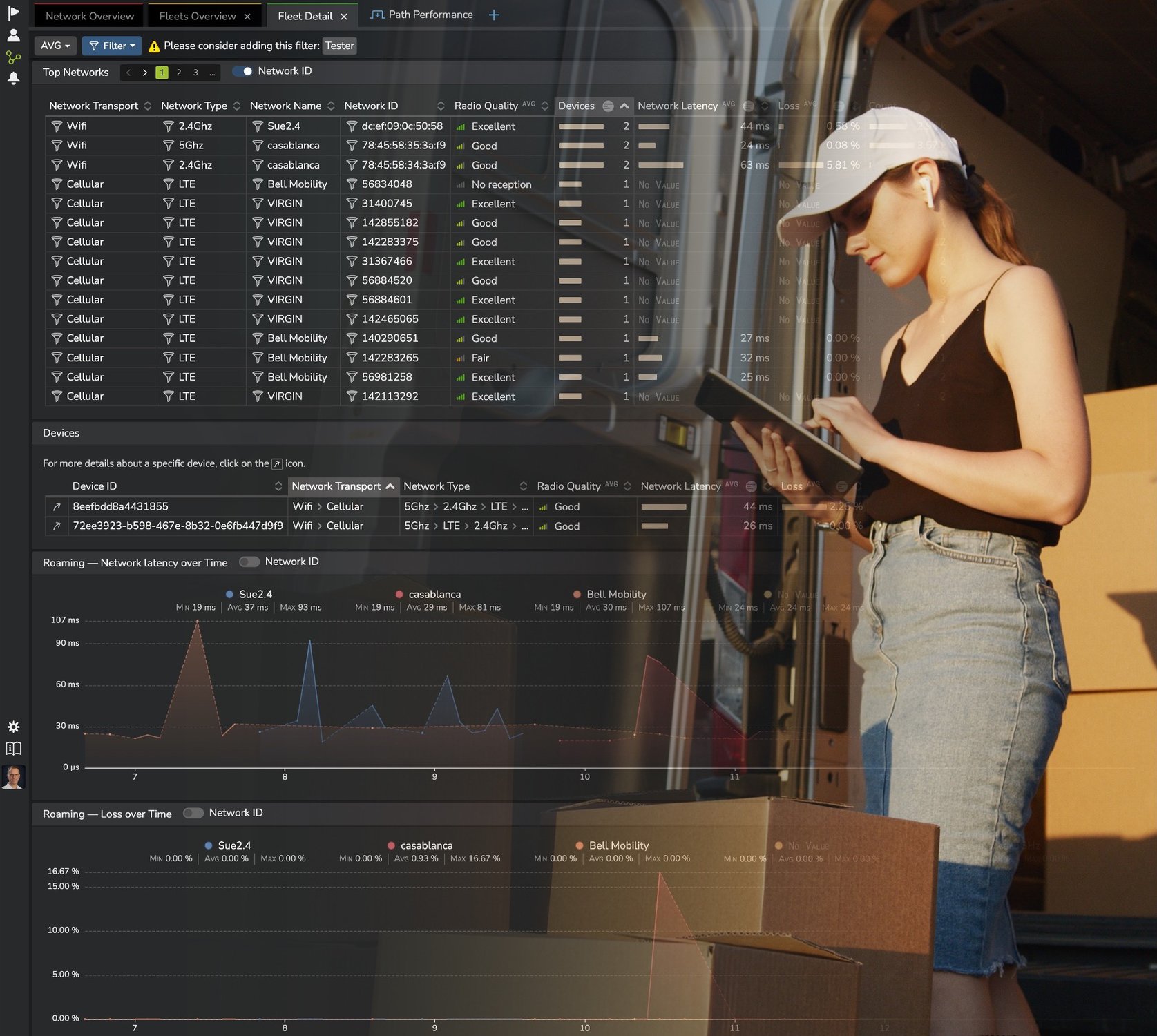
Anyone delivering applications over networks sees network response time as a critical factor for digital experience.
Let’s explain the basics of network latency:
- What is network latency?
- How to measure network latency?
- How it works? What drives to a slow or a fast response from the network.
- How to reduce it?
What is network latency? A definition
First, latency is the delay for a packet to travel on a network from one point to another. In most cases, we will refer to network latency as the time needed for a packet to move from a client / user to a server across the network.
Multiple flavors of network latency
Secondly, there are multiple ways to measure network latency:
- one way delay or one way latency: this is the time needed for a packet to go from one end (the user device) to another end (the server)
- two way delay or round trip time: this is the time needed for a packet to go from one end to the other end, and back

Depending on how you are try to measure latency, you will get either a round trip delay or a one way delay metric. As the conditions on the network vary and may be different in both directions, both types of measurements have pros and cons.
How to measure network latency?
Let’s look at the different ways to measure latency.
-
Traffic capture for TCP based traffic
Capturing packets will give a feel for round trip delay provided you capture TCP based traffic. The TCP/IP protocol includes an acknowledgment mechanism, which can be a good basis to evaluate the two way latency between a client and a server.
This approach has 2 significant drawbacks:
- First, acknowledgments can be delayed and handled in different ways depending on the system (read this article for more info).
- Second, the status of the systems (clients and servers) can impact the level of priority put on dealing with the acknowledgment mechanism; as an example, an overloaded server may delay ACKs and generate high RTT values, which do not align with real latency.
The metrics you can expect:
- RTT (Round Trip Time)
- CT (Connection Time) which measures the time required to execute the TCP session establishment (SYN – SYN/ACK – ACK). This has an upside: systems handle these steps with a higher priority – this means this rarely suffers a delay and does not generate wrong latency measurements. On the other hand it also a downside: it represents one and a half round trip, which is not easy to interpret.
- TTFB (Time To First Byte) was in the past sometimes considered an evaluation of latency, but this is not the case anymore. Earlier, some of us used to consider it as the time interval between the SYN packet and the first packet of response from the server. Nowadays, TTFB corresponds to the response time measurement between a web request and the first packet returned in response by the server. Even in its ancient definition, it reflects poorly network latency as it incorporates the server response time.
A side note on network latency measurement based on traffic capture: on UDP on can easily monitor Jitter (put in simple words the standard variation of latency) but cannot measure latency this way.
Put in a few words, you can measure latency with a traffic based approach by capturing traffic. The pro is that you do not need to control any of the two ends. The main inconvenient is that the metric is particularly imprecise.
-
Active testing of the network
You can also test your network latency by emitting packets and checking the time needed for them to make the one way or two way trip.
ICMP based testing
- The client computer sends an ICMP Echo request packet (commonly known as “ping”) to the target computer.
- The target machine receives the request packet and builds an ICMP Echo Reply packet.
The client computer will use the timestamps corresponding to the emission of the Echo Request and the reception of the Echo reply to calculate the round trip time.
The cons of ICMP are:
- ICMP is handled on networks in a different way than protocols which convey application data (mostly TCP and UDP). As an example it can get a higher or lower priority on operator networks.
- The handling of ICMP requests by network devices is a second class service and this may impact the quality of the latency measurement.
- ICMP handling may be disabled on the target device which may simply not respond to ICMP requests.
UDP / TCP based testing
You can send TCP or UDP packets and validate the reception of the packets.
The pro is that it is possible to measure one way latency and get more precise results.
The constraint is that you either need to have control of both ends or to use a testing protocol which has to be supported by both ends, for example TWAMP.
How it works: what drives network latency?
The 4 main factors that drive latency are:
-
Propagation
This is the time required for a packet to go from one interface of a network device to another network device’s interface over a cable. The rules of physics drive this factor, so you can expect it to be very stable (approximately the speed of light x 2/3). Put in a few words, the shorter the distance you need to cover in your network, the lower latency you will get.
2 & 3. Processing and Serialization
The serialization time on a network equipment is the time needed for a packet to be serialized for transmission on a cable. It depends on the packet size but remains constant and relatively negligible.
The processing time is a lot more variable on each network router or equipment on the network path. It depends on:
- the services provided by each router (bridging, routing, filtering, encrypting, compressing, tunneling)
- the capacity of the device vs its current load.
When considering the overall path, the number of hops / routers the traffic goes through will impact the overall time necessary for all the serialization and processing included in the total network latency.
4. Queueing
This is the time spent on average by every packet in the router queue.
It mostly depends on the size of the queue.
The size of the queue depends on the overall traffic size (vs its capacity) and its burstiness.
Longer queues will translate in additional latency and jitter.
How does it translate in latency for an overall network path?
Consider these drivers in the context of an end-to-end network path

The drivers for the end to end network path will be by decreasing order of importance:
Drivers and main factors influencing them
- Propagation
Geographical distance on the overall network path drives that time.
- Processing
The overall processing time depends on:
- Number of hops on the path
- Type of function activated
- Load vs. Capacity for each router
- Queuing
The overall queueing time depends on:
- Queue size (hence load vs capacity of the router or link)
- Number of hops on the path with queueing
- Serialization
The overall serialization time depends on:
- Number of hops on the path
- Packet size
Next steps
- First, understand the impact of latency on the digital experience of your customers and users
- Discover how you can measure network response times
- Third, find out what you can do in case of high latency? How to reduce it?