Dans cet article, nous expliquons les principales difficultés rencontrées par le protocole HTTP/1.1 qui ont conduit à l’adoption de HTTP/2. Nous présentons également quelques-unes des principales fonctionnalités ajoutées par HTTP/2 qui répondent aux limites des anciens protocoles.
Nous allons d’abord nous concentrer sur le protocole HTTP lui-même. Nous ne présenterons donc pas ici un aspect important qui est étroitement lié aux transactions web : la sécurité ! En effet, avec l’adoption de nouvelles normes comme HTTP/2 sont également apparus des protocoles de sécurité plus sûrs et plus performants comme TLS 1.3. Nous aborderons ce sujet important dans une autre série d’articles.
Selon W3Techs, 50,4 % (chiffres de mars 2021) de tous les sites Web mondiaux utilisent aujourd’hui le protocole HTTP/2 !
Les principaux réseaux de diffusion cloud (CDN) ont activé HTTP/2 sur leurs réseaux :
- keyCDN : 68 % de l’ensemble du trafic HTTPS était du HTTP/2 en avril 2016.
- Cloudflare : 52,93 % de tout le trafic HTTPS était HTTP/2 en février 2016.
- Akamai : plus de 15 % de l’ensemble du trafic HTTPS sur le réseau sécurisé d’Akamai (ESSL) était du HTTP/2 en janvier 2017. Ce pourcentage est faible par rapport aux autres CDN car HTTP/2 est activé de manière opt-in ; les CDN ci-dessus l’ont activé selon le principe de l’opt-out.
Depuis 2016, les principaux fournisseurs de cloud comme Amazon, Microsoft et Google ont intégré séquentiellement la prise en charge de HTTP/2 dans leurs différentes offres, comme les services d’équilibrage de charge, les services Web basés sur PaaS et les kits de développement logiciel.
Aujourd’hui, environ 96.7% de tous les navigateurs disponibles sur le marché prennent en charge le protocole HTTP/2.
Principales limitations de HTTP/1.1
Problème 1 : une seule demande à la fois
Le protocole HTTP/1.1 existe depuis plus de 20 ans. Basé sur la couche de transport TCP, c’est un protocole de type requête réponse : le navigateur web demande une ressource et attend la réponse. Avec HTTP/1.1, même si une requête HTTP ne nécessite pas une session TCP dédiée (comme c’était le cas dans HTTP/1.0), au sein d’une session TCP spécifique, une seule requête HTTP peut être envoyée à la fois. Cela rend HTTP/1.1 inefficace face à la complexité actuelle des sites web.
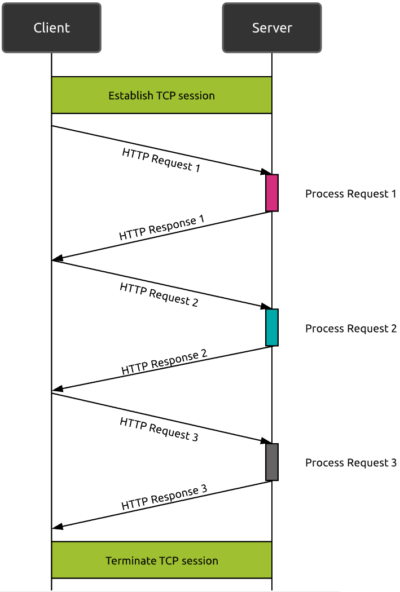
La solution proposée par HTTP/1.1 : le « pipelining »
La première tentative de HTTP/1.1 pour résoudre ce problème a consisté à introduire le concept de « pipelining ». Le pipelining consiste à envoyer plusieurs requêtes en parallèle sans attendre l’achèvement complet de la requête initiale.
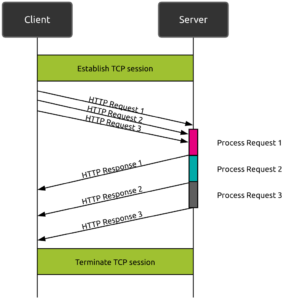
Avec le pipelining, même si le serveur peut recevoir plusieurs requêtes, il doit toujours traiter les réponses dans l’ordre des requêtes, ce qui peut bloquer l’ensemble du processus si une requête est lente. Cela introduit un problème potentiel appelé « Head Of Line Blocking » (HOLB).
HTTP/1.1 propose une solution de contournement qui consiste à autoriser plusieurs sessions TCP parallèles (généralement autour de 6 mais le nombre dépend du navigateur web). Cela ne résout pas complètement le problème HOLB, mais limite son impact à des sessions spécifiques.
Problème 2 : la duplication des données
Le second problème rencontré avec HTTP/1.1 est la duplication des données sur plusieurs requêtes parallèles. Le protocole HTTP étant un protocole « sans état », l’envoi de requêtes en parallèle via différentes sessions TCP implique l’envoi multiple des mêmes paramètres d’en-tête HTTP (cookies et autres paramètres tels que « User-agent »).
Cela a conduit au développement de techniques supplémentaires comme les « sprites d’images » et le « domain sharding »..
La solution proposée par HTTP/1.1 : « image sprite » et « domain sharding ».
- « Image sprite » correspond à la combinaison de plusieurs images (d’un CSS par exemple) en une seule, de sorte que plusieurs images puissent être envoyées dans une transaction de type requête réponse.
- Le Le « domain sharding » tend à résoudre le problème du nombre limité de sessions TCP concurrentes dans un pipeline (un exemple de 3 sessions maximum est présenté sur les figures ci-dessous). Avec cette technique, les demandes de ressources sont réparties sur plusieurs domaines afin d’augmenter le nombre de connexions TCP parallèles possibles.

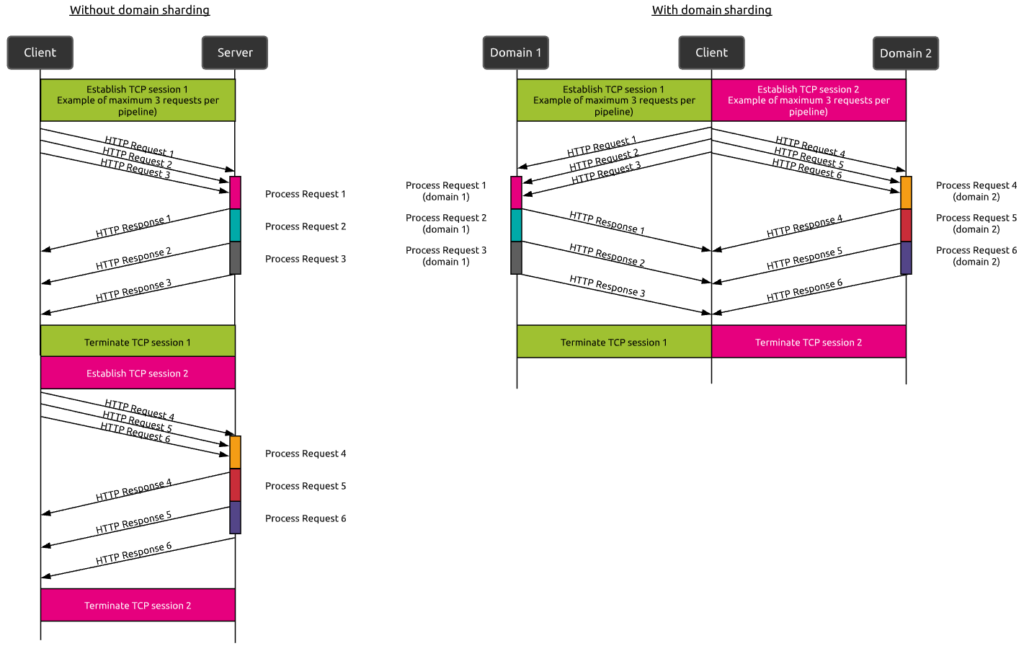
En quoi HTTP/2 diffère-t-il de HTTP/1.X ?
HTTP/2, ratifié en mai 2015 par l’Internet Engineering Task Force (IETF) sous la RFC 7540 est le successeur de HTTP 1.1.
Les principaux objectifs de cette initiative étaient de résoudre les problèmes perçus en matière de performances et d’efficacité, de sorte que le HTTP/2 puisse améliorer les performances du web. Il offre également une sécurité renforcée.
Nous pouvons résumer les principales améliorations de HTTP/2 en deux catégories (si nous excluons les aspects de sécurité) :
- La façon dont le serveur transfère les données au client
Le formatage des données binaires et la compression des en-têtes sont des moyens d’optimiser ce transfert de données - La manière dont se déroule la communication entre un client et un serveur.
Les techniques de multiplexage et de push des serveurs l’améliorent principalement.
Formatage des données
Contrairement à HTTP/1.1, qui conserve toutes les requêtes et réponses au format texte brut, HTTP/2 utilise la couche de frame pour encapsuler tous les messages au format binaire, tout en conservant la sémantique HTTP, comme les méthodes et les en-têtes. Au niveau de la couche applicative OSI, les messages sont toujours créés dans les formats HTTP conventionnels, mais la couche sous-jacente convertit ensuite ces messages en binaire. Ainsi, les applications web créées avant HTTP/2 peuvent continuer à fonctionner normalement lorsqu’elles interagissent avec le nouveau protocole.
La conversion des messages en binaire permet à HTTP/2 d’essayer de nouvelles approches de la transmission des données qui ne sont pas disponibles dans HTTP/1.1. C’est la base qui permet toutes les autres fonctionnalités et optimisations de performances fournies par le protocole HTTP/2.
Compression de l’en-tête
Le transfert de données du serveur au client consomme de la bande passante et prend du temps. Une bande passante restreinte ou une charge utile de données énorme à transférer aura bien sûr un impact sur les performances globales. Ainsi, tout moyen d’optimiser les données à transférer est un atout. Un bon exemple est la mise en cache, comme nous l’expliquons dans notre article « Améliorer les performances web avec la mise en cache du contenu« .
HTTP prend en charge les mécanismes de compression des données depuis des lustres. Cependant, les en-têtes sont envoyés sous forme de texte non compressé et de nombreuses données redondantes sont envoyées à chaque transaction.
HTTP/2 utilise les spécifications HPACK pour compresser un grand nombre de trames d’en-tête redondantes. Pour ce faire, le client et le serveur conservent une liste des en-têtes utilisés dans les requêtes précédentes. HPACK compresse la valeur individuelle de chaque en-tête avant de la transférer au serveur. Ce dernier recherche ensuite les données codées dans une liste de valeurs d’en-tête précédemment transférées afin de reconstituer les informations complètes de l’en-tête.
Multiplexage
Dans notre article « Pourquoi la latence du réseau conditionne la performance numérique« , nous expliquons comment le protocole TCP influe sur les performances du web. La réduction du nombre d’allers-retours nécessaires est un facteur clé de performance, notamment pour les communications longue distance.
Avec HTTP/1.1, il existe une limite en termes de nombre de transactions web par session TCP. Comme nous l’avons vu précédemment, des techniques comme le pipelining et le domain sharding permettent de réduire l’impact sur les performances des établissements de sessions TCP multiples. Mais elles ne résolvent pas complètement le problème. L’établissement de sessions TCP consomme des ressources et du temps !
HTTP/2 introduit la technique du multiplexage pour relever ce défi.
Au lieu d’utiliser une session TCP dédiée par élément demandé (HTTP/1.0) ou de devoir traiter les requêtes dans l’ordre (HTTP/1.1 avec pipelining), cette technique permet au navigateur d’interroger tous les éléments au sein de la même connexion TCP :
Cette technique résout le problème du blocage de la tête de ligne (HOLB) et rend le partage de domaine (“domain sharding”) inutile
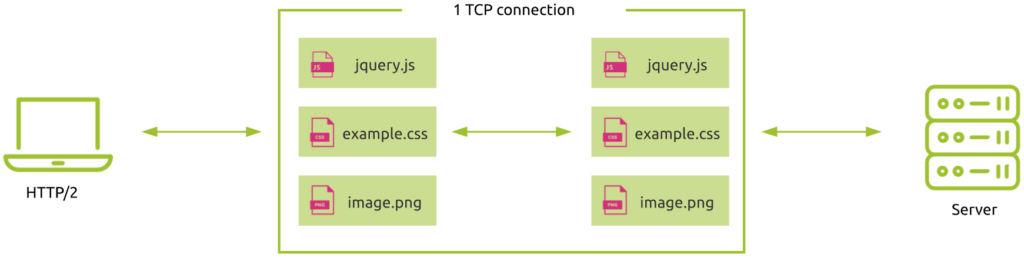
Si l’on considère que la latence du réseau entre New York et Sydney est d’environ 80 ms, l’utilisation de HTTP/2 réduit le temps réseau de 3 allers-retours (2 handshakes TCP) par rapport à HTTP/1.0. Cela correspond à un gain de temps de 240 ms !
Push serveur / Server push
Le chargement des ressources dans le navigateur est difficile !
Comme nous l’avons vu précédemment, les performances sont étroitement liées à la latence du réseau. En outre, l’événement d’exécution est extrêmement important. Par exemple, le chargement d’un JavaScript bloque le rendu d’une page Web (le processus d’analyse HTML est arrêté jusqu’à ce que le JavaScript soit chargé). C’est également le cas pour les ressources CSS (Cascading Style Sheets).
Ainsi, deux des questions majeures dans l’optimisation des performances des applications web sont : « Comment pouvons-nous charger les ressources plus efficacement, et quelles sont les ressources les plus importantes à charger en premier ? ».
Dans HTTP/2, un serveur peut anticiper le fait que le navigateur aura besoin de ressources supplémentaires plus tard en les envoyant de manière proactive sans attendre de nouvelles demandes du navigateur.. C’est ce qu’on appelle le « Server Push ».
Dans la figure suivante, la demande de la page HTML d’index déclenche automatiquement l’envoi du JavaScript, de la feuille de style et de l’image requis par le serveur, sans aucune demande supplémentaire de la part du navigateur.
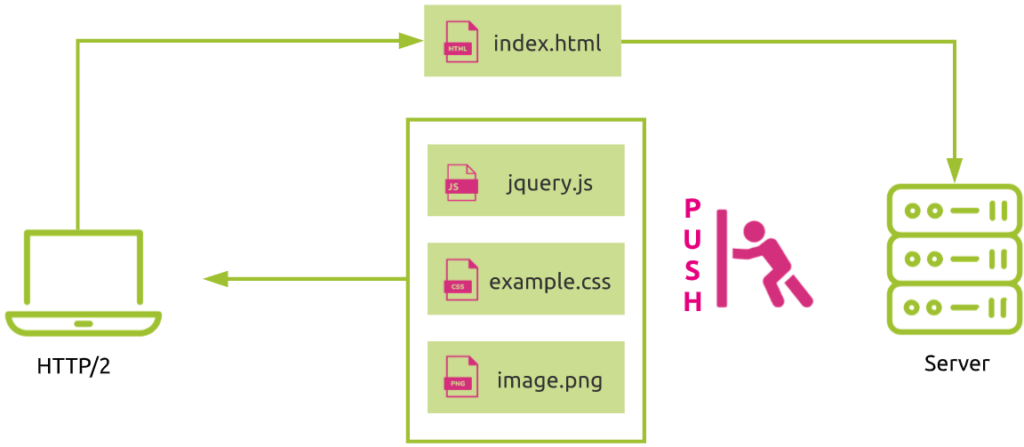
L’utilisation du push serveur peut améliorer considérablement les performances du web.
HTTP/2 est-il la solution ultime ?
D’après les paragraphes précédents, vous pourriez conclure que l’utilisation de HTTP/2 sera la solution idoine pour améliorer les performances du Web dans tous les types de scénarios. Est-ce vraiment le cas ?
Examinons deux cas qui illustrent des situations où HTTP/2 n’est peut-être pas le bon protocole à utiliser.
Utilisation du multiplexage dans des conditions de congestion du réseau
Supposons que vous utilisiez la technique du multiplexage en cas de congestion du réseau.
Étant donné que plusieurs transactions web sont transmises par la même connexion TCP, elles sont toutes également affectées par cette dégradation (perte de paquets et retransmission), même si les données perdues ne concernent qu’une seule requête !
Vous voyez donc comment des techniques avancées qui devraient améliorer les performances peuvent dans certains cas aggraver la situation.
C’est là que le protocole TCP touche à sa fin et que de nouveaux protocoles (QUIC et HTTP/3) utilisent UDP comme couche de transport, mais c’est une autre histoire qui sera abordée dans de futurs articles.
Utilisation du push serveur en combinaison avec des techniques de mise en cache
Avec le push serveur, le serveur envoie de manière proactive des ressources au navigateur du client.
Néanmoins, dans le cas où le navigateur a déjà les données dans son cache, est-ce une bonne idée de les envoyer quand même ? Bien sûr que non ! Cela consommerait inutilement des ressources réseau et système.
Le principal problème ici est que le serveur n’a aucune connaissance de l’état du cache du client. Parmi les autres solutions de contournement, une solution à ce problème est appelée « Cache Digest ». Un condensé est envoyé par le navigateur pour informer le serveur de toutes les ressources disponibles dans son cache, afin que le serveur sache qu’il n’a pas besoin de les envoyer.
Malheureusement, ce type de technique est encore sujet aux incohérences des navigateurs et au manque de compatibilité des serveurs.
Récapitulatif
Les technologies web évoluent en permanence pour offrir la meilleure expérience utilisateur possible.
HTTP/2 apporte des améliorations majeures par rapport à la norme HTTP/1.X précédente. Les nouveaux protocoles comme HTTP/3 (anciennement appelé QUIC – Quick UDP Internet Connection) joueront certainement un rôle important dans le développement du web à l’avenir.
Néanmoins, comme nous l’avons vu dans cet article, le diable se cache souvent dans les détails. Des capacités améliorées peuvent parfois conduire à des résultats inattendus. L’efficacité des techniques décrites dépend de facteurs externes comme les conditions du réseau et le support du navigateur/serveur.
C’est pourquoi il est si important de pouvoir les surveiller :
- non seulement les performances du web elles-mêmes en termes de protocoles et de visibilité des transactions,
- mais aussi la façon dont les clients se connectent aux ressources du web (localisation, performance du réseau, …).
C’est ce que fait Kadiska en fournissant un suivi de l’expérience de bout en bout : en savoir plus !