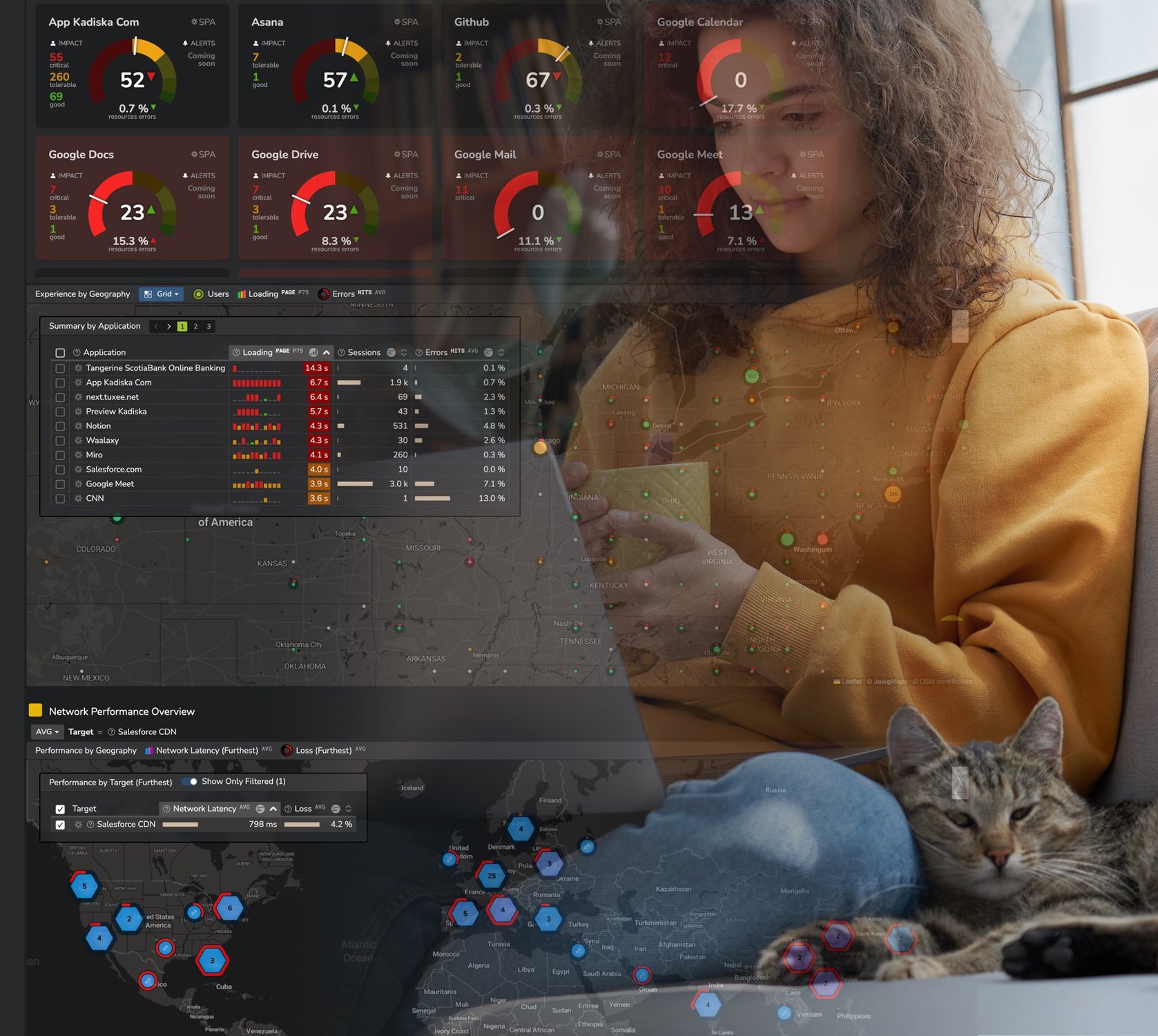
Pourquoi la latence entre utilisateurs et services cloud est-elle si importante ? Excellente question. La réponse tient en deux éléments clés :
- L’adoption du SaaS et des services cloud : la plupart des applications métier ont déjà migré d’une livraison “on-premise” depuis un datacenter vers un mode SaaS ou basé sur le cloud. La pandémie de Covid a accéléré ce changement. Ceci signifie qu’une performance dégradée des applications SaaS ou Cloud se traduit par une perte de productivité massive pour la plupart des organisations. Vous n’êtes pas sûr de cela ? Lisez plutôt cet article.
- La latence conditionne l’expérience utilisateur ou la performance ressentie par les utilisateurs : c’est assez simple, plus la latence est élevée entre un utilisateur et les différents éléments d’une plateforme applicative, pire sera la performance ressentie. Si vous avez un doute, je vous recommande de lire cet article.
Qu’est-ce qui fait que la latence d’un utilisateur vers une plateforme SaaS ou cloud est plus ou moins élevée ?
Comment fonctionne la latence réseau ?
En revenant aux fondamentaux, la latence réseau est l’intervalle de temps nécessaire pour qu’un paquet aille d’un point à un autre, par exemple d’un utilisateur à une plateforme cloud (et le retour correspondant).
Qu’est-ce qui conditionne la latence sur les réseaux ?
- Propagation : comprenez la distance entre les deux points ou les deux correspondants.
- Traitement réseau et sérialisation : exprimé en termes simples, il s’agit du temps nécessaire pour traverser les équipements actifs tels que les routeurs, les firewalls, répartiteurs de charges et proxys etc… ; celui-ci dépend (1) du nombre d’équipements sur le chemin, (2) du traitement qu’ils effectuent et (3) de leur niveau de performance respectif.
- “Queueing” : en cas de congestion sur un de ces équipements, les paquets sont placés dans une file d’attente, ce qui retarde le traitement et accroît donc la latence.
Si vous cherchez de plus amples informations sur ce sujet, veuillez lire cet article.
Il y a donc 3 critères principaux : la distance entre l’utilisateur et le serveur, le nombre d’équipements réseau sur le chemin, la charge et la performance de chacun de ces équipements.
Comprendre où sont situés les utilisateurs et où ils se connectent
Quand on cherche à évaluer la latence entre utilisateurs et cloud, le premier élément à comprendre est la distance physique entre eux et donc :
- Où sont localisés les utilisateurs ?
- Où sont-ils redirigés par les services SaaS ou cloud ?
Dans cet article, nous ferons l’hypothèse que vous savez où se situent vos utilisateurs.
La principale question est donc vers quelle(s) destination(s) les plateformes SaaS les redirigent.
Comment les plateformes SaaS et cloud redirigent les utilisateurs ?
La plupart des plateformes procèdent de la façon suivante :
- Récupérer l’adresse IP de l’utilisateur
- La rechercher dans une base de géolocalisation pour évaluer leur position géographique (grâce à des services tels que MaxMind, IPWhois.io ou d’autres)
- Les rediriger vers le nœud le plus proche grâce au service DNS. Les enregistrements DNS seront résolus de façon différente en fonction de la localisation.
Une fois ceci effectué, il y a deux éléments qui peuvent affecter négativement la latence des utilisateurs vers le cloud :
- La capillarité insuffisante de votre fournisseur SaaS ou de ses sub-processeurs
- Les erreurs de localisation
Comprendre la capillarité de la plateforme de votre fournisseur SaaS
C’est assez simple : depuis combien de points géographiques votre fournisseur SaaS (ou ses sub-processeurs) fournit-il son application ? Quel est le niveau de proximité avec vos utilisateurs ?
Prenons deux exemples :
Un fournisseurs hébergeant l’application dans ses propres datacenters
Dans l’exemple ci dessous, nous analysons le chemin réseau vers en.wikipedia.org depuis plusieurs points ; Wikimedia (qui héberge le fameux Wikipedia) exploite plusieurs datacenters dans le monde. Comme vous le verrez, en fonction du point de test le chemin réseau varie :
1. En testant depuis plusieurs points dans le même pays (ici depuis les Etats Unis), nous obtenons la même résolution DNS pour en.wikipedia.org et le chemin se termine toujours vers le même point géographique.

2. En testant depuis plusieurs points dans différents pays (et ici même différents continents), nous obtenons des résolutions DNS distinctes, menant à des chemins réseau terminant dans différents datacenters.

Cas d’une application hébergée dans un environnement cloud à grande échelle
Prenons l’hypothèse que le fournisseur SaaS utilise une infrastructure cloud à grande échelle. Dans l’exemple ci-dessous, nous testons le chemin réseau depuis plusieurs points aux Etats Unis vers un même nom d’hôte. Le fournisseur d’hébergement de l’application est AWS (Amazon Web Services).
Comme vous pouvez le voir, il y a plusieurs résolutions DNS : en fonction du temps et de la localisation des points de tests, nous sommes redirigés vers différentes adresses IP au sein de l’infrastructure d’AWS. Selon la localisation des hôtes, cela se traduit par une variation de latence qui peut affecter l’expérience utilisateur de façon significative.

Prenons un second exemple d’un nom d’hôte correspondant à un CDN (Content Delivery Network).

Toutes les plateformes cloud ne se valent pas.
Toutes les plateformes d’hébergement ont une capillarité et une couverture géographique qui leur est propre. Le manque de couverture peut être problématique pour une organisation et ne pas poser de difficulté à une autre : cela dépend de la bonne adéquation avec la distribution géographique des utilisateurs.
Est-ce que la géolocalisation fonctionne correctement pour vos utilisateurs ?
Le principe de base de tout ceci repose sur la traduction des adresses IP des utilisateurs en position géographique. La géolocalisation n’est pas sans défaut. Elle peut tout simplement renvoyer une valeur incorrecte. Certaines adresses IP peuvent être mal renseignées dans les bases whois telles que le RIPE et certains opérateurs ne maintiennent pas les informations géographiques pour tous leurs préfixes de façon régulière.
Erreurs de géolocalisation
La conséquence la plus courante du manque d’exactitude de ces données est la suivante : la localisation de certains utilisateurs est mal interprétée et ces derniers sont redirigés vers un nœud géographiquement éloigné.
Voici un exemple : les deux stations de test sont situées en Inde ; elles sont connectées au travers de deux opérateurs distincts (respectivement Reliance Jio et Airtel, les deux opérateurs les plus importants du pays). Alors qu’une des stations tente de joindre un service cloud de passerelle sécurisée, il est redirigé localement mais la seconde station est quant à elle redirigée vers les Etats Unis.

Changements fréquents de redirection
On peut aussi observer que la redirection depuis une adresse IP spécifique change en fonction du temps (au cours d’un même jour) vers des hôtes situés dans différents pays pour le même FQDN (hostname). Prenez l’exemple ci-dessous de pmu.fr :

Dernier facteur important : la longueur et la qualité du chemin réseau
En faisant l’hypothèse que vos utilisateurs sont chanceux, c’est-à-dire qu’ils sont redirigés vers le noeud le plus proche (ce qui est fort heureusement le cas le plus courant), les conditions réseau entre l’utilisateur et le serveur peuvent varier de façon significative et impacter la latence.
Chaque opérateur qui participe au chemin réseau peut impacter la latence en changeant la route, en ayant des routeurs ou des liens montrant des signes de congestion qui ajoutent de la latence sur le chemin de bout en bout.
Si nous considérons l’exemple ci-dessous, nous observons un pic de latence (qui passe de 10ms à plus de 60ms) depuis un point de test placé en Turquie vers un hôte hébergé par CloudFlare.

En analysant le chemin de manière détaillée sur les deux intervalles de temps, on peut voir que la route empruntée est différente :


Et aboutit à des différences de latence énormes !
Comment mesurer la latence utilisateur – cloud ?
Visualiser où sont localisés les utilisateurs, où les applications SaaS les renvoient et quelle latence en résulte est la clé pour optimiser l’expérience utilisateur.
Kadiska offre un service pour superviser tous ces paramètres ; pour découvrir comment cela fonctionne, suivez ce lien !