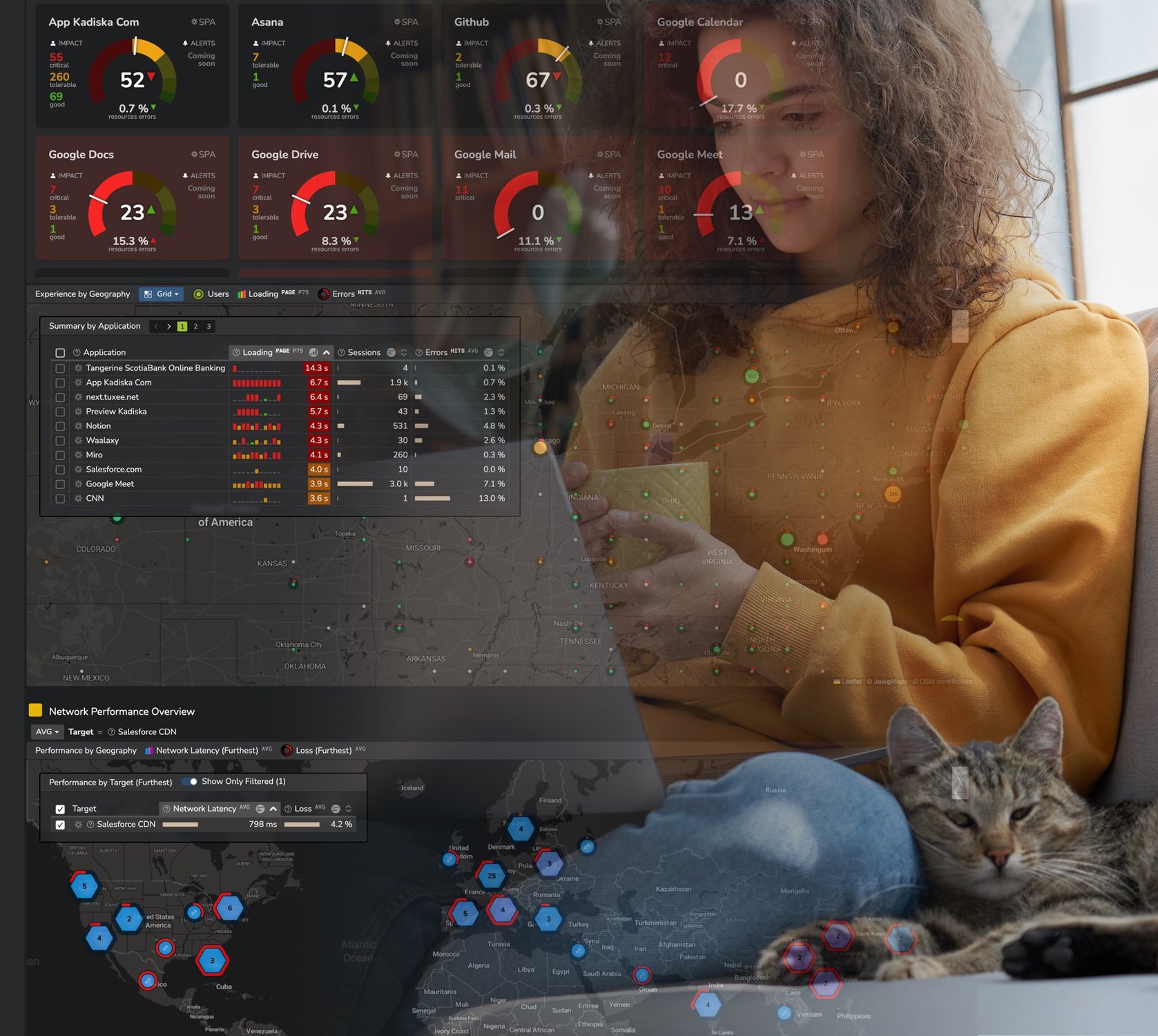
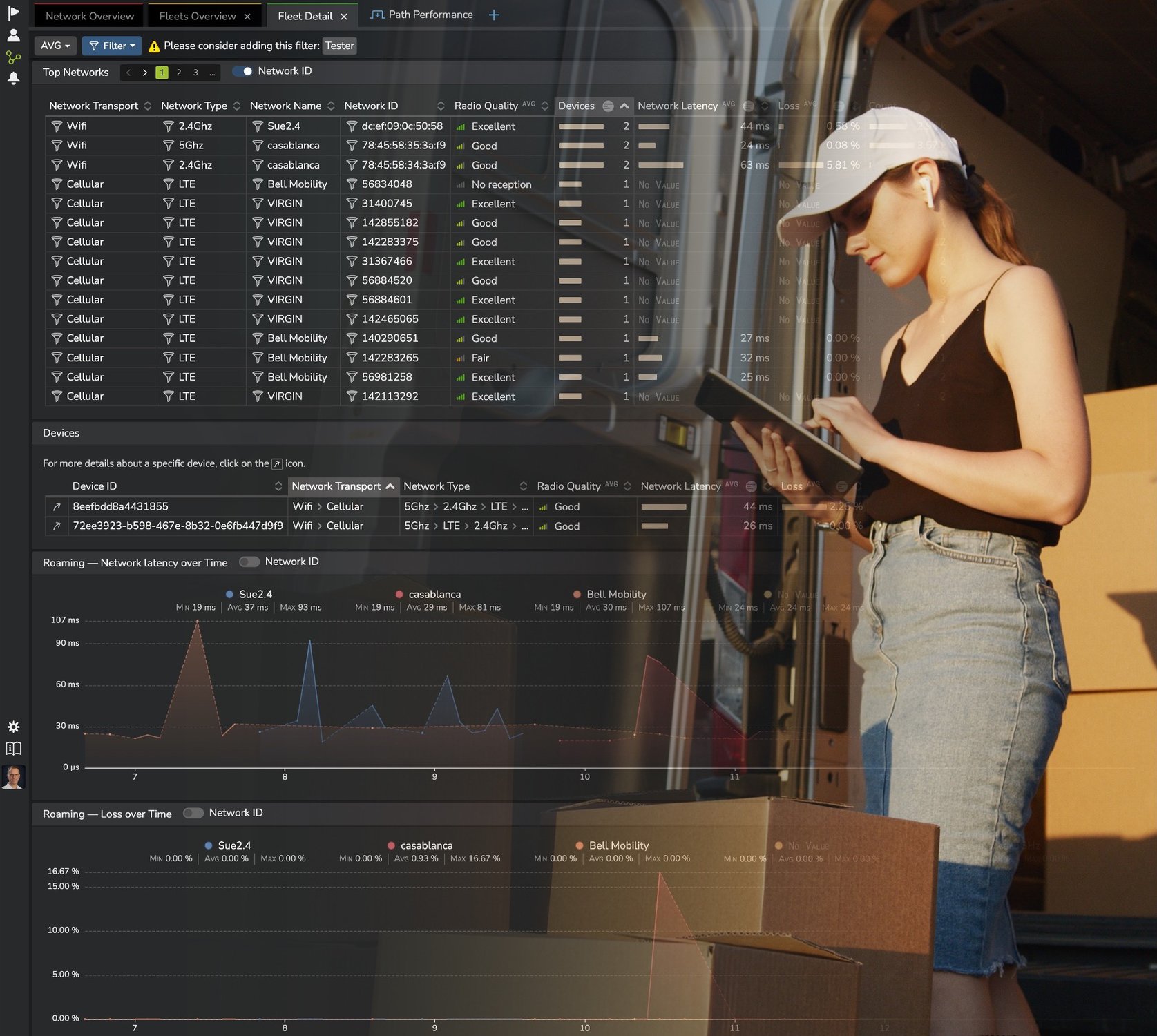
Avec un mélange de fournisseurs de edge compute et de connectivité, il peut être difficile de déterminer les garanties de performances ou de résoudre rapidement les problèmes de latence ou d’application. Imaginez acheter des services de calcul de périphérie multi fournisseurs auprès d’un fournisseur de services managés qui offre une connectivité via plusieurs fournisseurs de services de télécommunications en gros et régionaux sur un SD WAN managé !
Cette réalité rend difficile l’achat d’un service de Edge Compute garanti de bout en bout et soutenu par un SLA, non seulement parce que de nombreuses parties sont impliquées, mais aussi parce qu’il n’est jamais facile de déterminer l’origine des problèmes.
Cette combinaison de plusieurs fournisseurs de services, emplacements et domaines d’hébergement fait de la détection, de l’isolement et de la résolution des dégradations de performances un élément essentiel d’une stratégie de calcul Edge réussie. Les équipes d’exploitation et de performance informatiques doivent tenir compte de ce qui peut avoir un impact sur les performances des applications pour s’assurer qu’elles sélectionnent les meilleurs fournisseurs, valident les déploiements et résolvent les problèmes rapidement.
Ce billet de blog explique les nombreuses façons dont la latence peut être affectée lors de l’accès aux ressources cloud.
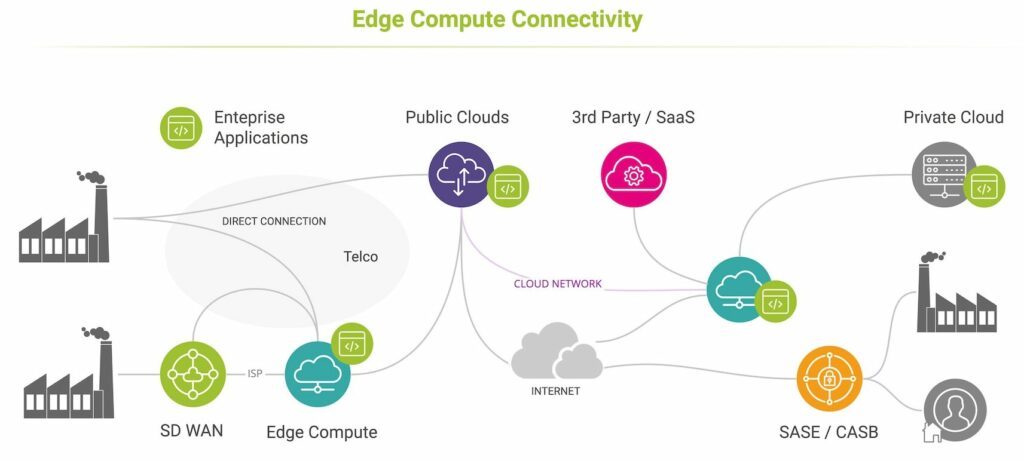
Qu’est-ce qui a un impact sur les performances de calcul en périphérie ?
Le Edge Computing est conçu pour des performances élevées, mais par définition, les petits centres de données régionaux et les «pico clouds» comme ceux fournis par la famille AWS Snow ont des ressources, une résilience et une évolutivité limitées. Vous pouvez tout savoir sur les origines du calcul edge compute, comment il est déployé et les principales applications pour le calcul de périphérie dans cet article recommandé.
Voici les cinq principales raisons de surveiller les performances de l’edge computing:
- Assurez-vous que les charges de travail ne submergent pas la capacité limitée de calcul de l’edge computing. Cela peut être facilement détecté par les temps de réponse et de transaction du serveur, les taux de transfert et les erreurs d’application.
- Détectez les changements d’emplacement d’hébergement. Si l’orchestration dynamique est utilisée, il est également important de savoir si les charges de travail ont changé d’emplacement ou se sont déplacées vers des clouds publics lorsque la capacité de calcul de périphérie locale est saturée.
- Recevez des alertes de panne. Les performances de calcul en périphérie peuvent être affectées par des pannes dans les domaines du cloud périphérique ou de la connectivité, qui sont tous deux très dynamiques. Les réseaux d’accès locaux sont moins résilients et moins diversifiés que les réseaux à haute capacité que les entreprises utilisent pour accéder aux centres de données cloud à grande échelle.
- Identifiez la congestion causée par les transferts importants. La congestion causée par des transferts importants entre les sites d’entreprise et les emplacements de cloud périphérique peut entraîner une perte de paquets et une latence lorsque le trafic est retransmis. Ceci est particulièrement courant dans les applications d’analyse liées à la vidéo (par exemple, la vision artificielle, la détection de visages et d’objets) qui combinent de gros volumes de données avec des exigences de performances à faible latence.
- Détecter les latences anormales. L’augmentation de la latence peut provenir des couches de calcul ou d’application, de la configuration du réseau, des changements de chemin ou des retards de configuration de la connectivité introduits par DNS et TLS. Lorsque SASE / CASB est utilisé pour gérer l’accès au cloud, la connectivité peut être affectée car le trafic est redirigé via des proxys sécurisés avant d’être acheminé le long du chemin réseau entre eux et les nœuds de calcul en périphérie.
- Déterminez l’impact des services distants sur les performances. Lorsque les applications périphériques utilisent des services hébergés ailleurs, elles peuvent être affectées par les retards de transaction et de traitement introduits par la connectivité et les performances de ces ressources distantes. Vous pouvez en savoir plus sur les défis liés aux performances de la connectivité hybride dans cet article de blog.
Enfin, Comment surveillez-vous les performances de calcul en périphérie (ou “edge compute”) ?
Avec autant de variables qui peuvent avoir un impact sur les performances, il est essentiel d’avoir une visibilité complète sur la chaîne complète de livraison des applications, du client à l’application de calcul en périphérie.
Voici quelques éléments essentiels de la surveillance des performances de calcul en périphérie :
- Performances et réactivité des applications et du calcul – retards et erreurs de réponse des transactions et du serveur.
- Accessibilité et fiabilité du calcul Edge par application et emplacement de l’utilisateur.
- Routage réseau, longueur de chemin, latence et performances de perte entre tous les emplacements des utilisateurs et les emplacements des nœuds périphériques.
- Performances du réseau sous-jacent de bout en bout par saut et fournisseur au fil du temps.
- Impact des performances des services SASE/CASB, DNS et TLS sur la latence et l’accès local.
- Surveillance de l’expérience utilisateur pour les applications hébergées en périphérie dépendant de plusieurs hôtes distants, CDN ou services tiers.
- Performances du réseau entre la périphérie et les clouds publics/privés.
Les solutions doivent être compatibles avec une infrastructure cloud de pointe moderne et hautement dynamique :
- Légère et rentable.
- Évolutif de la couverture régionale à la couverture mondiale.
- Réactif à l’évolution des emplacements périphériques, des applications et des charges de travail.
- Approche non intrusive, sans agent/side-car.
- API ouvertes pour s’interconnecter avec les plateformes d’orchestration, de SD WAN et d’observabilité.
Voir Kadiska en action
Kadiska propose une solution de surveillance de l’expérience numérique autonome qui intègre les performances des applications et du réseau avec un dépannage guidé et des informations d’optimisation – conçu pour les applications modernes SaaS, cloud et en périphérie.
Prenez 20 minutes et essayez-le dans votre réseau.